어제에 이어 오늘도 자료구조를 한다,,, 오늘 큐랑 해시테이블 강의 들었는데 해시테이블은 아직도 이해를 못해서 정리할 수 없다,,,,
물론 글을 작성하면서 정리가 될 수도 있겠지만 조금 더 이해를 하고 난 다음에 정리하고싶어서 오늘은 큐만 다루도록 하겠다...
큐(Queue)?
큐는 데이터를 임시로 저장하는 자료구조로 데이터가 입력된 순서대로 처리되어야 할 때 사용된다.
어제의 스택과 달리 FIFO(First In First Out)의 특징을 가지고 있다.
즉, 먼저 입력된 것이 먼저 출력되는 구조이다.
파이썬에서는 리스트를 통해 큐를 구현할 수 있다
append를 사용해 마지막에 데이터를 삽입하고
pop(0)으로 리스트의 가장 첫 번째 데이터를 꺼낼 수 있다
그리고 파이썬의 collections의 deque를 통해 효율적으로 큐를 구현 할 수 있다
deque는 리스트와 달리 양쪽에서 데이터를 삽입하고 꺼낼 수 있는 구조이다
appendleft()와 popleft()를 통해 리스트의 앞에서 데이터를 추가하고 꺼낼 수 있으며
append()와 pop()을 통해 리스트의 뒤에서 데이터를 추가하고 꺼낼 수 있다
그렇다면 리스트의 pop(0)과 deque의 popleft()에는 무슨 차이가 있는가?
리스트의 pop(0)은 시간복잡도가 O(n)이지만 popleft() 시간복잡도가 O(1)이다.
from collections import deque
import time
a = [i for i in range(100000000)]
b = deque(a)
start = time.time()
print("=============================================")
a.pop(0)
print("a.pop(0)의 걸린시간 : ", time.time() - start)
print("=============================================")
start = time.time()
b.popleft()
print("b.popleft()의 걸린시간 : ", time.time() - start)
print("=============================================")
1억을 가진 리스트에서 각각 첫 번째 요소들을 제거 할 때 걸리는 시간은 다음과 같다

a.pop(0)은 약 0.1초
b.popleft()는 2.14*10^(-6)
따라서 popleft를 사용했을 때 시간이 훨씬 적게 소요되는 것을 알 수 있다
왜 이런 차이가 발생하는가?
리스트에서 첫 번째 요소를 제거하고나면 뒤의 요소들을 앞으로 당겨오는 작업이 필요하다

이렇게 pop(0)을 이용해 데이터를 가져온 뒤 빈 자리에는
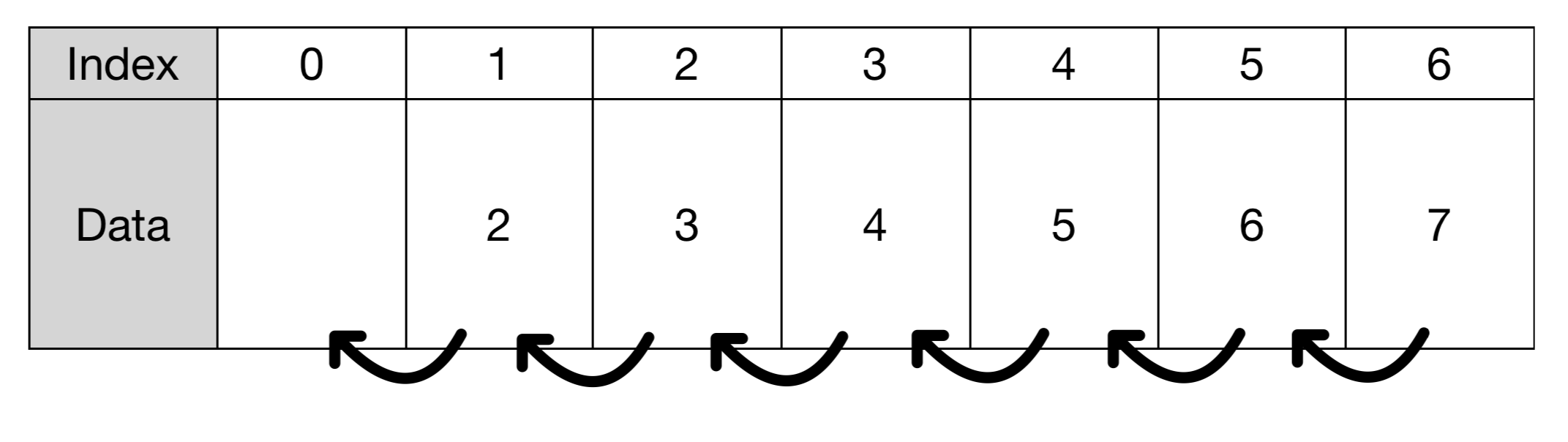
뒤의 값을 하나씩 앞으로 가져오는 작업을 하게 된다
따라서 O(n)이라는 시간 복잡도를 가지게 되는 것이다.
큐에서는 연결리스트처럼 포인터의 값만 조정한다.
front+=1의 작업만 수행하므로 시간 복잡도가 O(1)이 되는 것이다.
그렇다면 큐를 사용하는 것이 무조건 유리한 것인가?
큐의 용도로 사용할 때는 deque를 사용하는 것이 좋지만
인덱스를 사용해 데이터에 접근하거나 스택의 용도로 사용할 때는 리스트 그대로 사용하는 것이 유리하다고 한다
deque는 인덱스를 갖지 않기 때문이라고는 하지만,,,

인덱스로 접근해도 출력이 되기는 하네요..?
다만 시간이 조금 더 오래 걸릴 뿐
사실 여기까지는 그래도 할만 했는데 해쉬테이블이랑 알고리즘 들어가면서 멘탈 와르르멘션,,,,
나 잘 할 수 있겠지,,,,

'[내일배움캠프]스파르타코딩클럽 AI 웹개발 > Today I Learned' 카테고리의 다른 글
| [내일배움캠프 14일차 TIL] Git&GitHub (0) | 2024.07.11 |
|---|---|
| [내일배움캠프 13일차 TIL] 자료구조 - 트리 (0) | 2024.07.10 |
| [내일배움캠프 11일차 TIL] 자료구조 - 연결리스트(Linked list)/스택(Stack) (0) | 2024.07.08 |
| [내일배움캠프 10일차 TIL] 이중리스트 풀기 with python (0) | 2024.07.05 |
| [내일배움캠프 09일차 TIL] 파이썬에서 클래스 이해하기 (0) | 2024.07.04 |



